
Multiple Pipelines
Automated testingFor fast processing of the pipeline at commit, others in // are created to run the slowest and lowest value tests in the background

Description
A so-called pipeline is a shared robot that processes each step of a delivery process, from the build to its deployment. It aims to automate a Product Increment delivery ready to be deployed [Humble 2011].
A pipeline helps to [Edelman 2018]
- Move faster in order to be able to respond to the changing needs of the business more quickly
- Improve reliability to learn from old lessons, and improve quality / stability of the overall system.
A pipeline is usually composed with
- an “Continuous Integration” phase (CI) which consists generally in retrieving the source, compiling it, running the tests and other controls to ensure quality standards (quality gates)
- a “Continuous Delivery” phase (CD) which consists in deploying the delivery bundle in the appropriate environment - this environment may also be built during this phase
- a monitoring phase which takes care of feedbacks from End Users and generate improvement on the Solution through that product backlog or immediate corrective actions when major incidents occur ; many terms may refer to this part such as “Continuous Exploration” [SAFe 2021-46] or “Continuous Operation” [Deloitte 2020]
The phases may include different steps such as
- DevSecOps features
- Release tagging at the end of CI
- Infrastructure setup at CD time thanks to “Infrastructure as Code” (IaC) capabilities with immutable servers
Those phases depend on the product and organization maturity level.

This CI idea arose with Grady Booch who first proposed the term in his book “Object-Oriented Analysis and Design with Applications” first edited in 1991 which also mentioned a “Continuous Testing” paradigm [Booch 1994]. Then the first attempts were done in 1996 with Kent Beck’s Extreme Programming (XP) at Daimler Chrysler [Fowler 2006] with a pipeline named “Cruise Control” in 2001: [Cosgrove 2021].
Deployment can be done in several ways [Ratcliffe 2012]:
- Big bang: everything is deployed at once
- Big Bang with Rolling Releases: iterative sets of features releasing
- Rolling Releases: releasing features as soon as they are ready
- Continuous Delivery: releasing pieces of code as soon as they are good enough
- Continuous Design: CD combined with iterative Design Thinking [Lewrick 2018], Empathy Map [Gray 2009], Lean UX [Gothelf 2013] or Lean Startup [Ries 2012]
Those strategies infer different release sizes, time to value and amount of risk.

With a pipeline, changes can be made with high frequency in production to ensure continuous improvement instead of a "big bang" approach which reduces the risk inferred by big bang strategies [Duvall 2007] [Nygard 2018]. This “doing things continuously” mindset is often met in agile: “if it hurts, do it more frequently, and bring the pain forward” [Humble 2011]. Thus, a full build pipeline should be run on every commit, to continuously deliver the Product Increment [Nygard 2018].
The obvious drawback of CI combined with CD is to blindly introduce bugs in production [Edelman 2018], hence the need to repeatedly assess the quality level before the CD phase starts. To avoid this pitfall, the pipeline relies on
- an “Automate everything you can” mindset to prove the work is done at every new change [Humble 2011]
- a Unit Tests set that triggers bugs in order to control regression; this is named “Writing Tests for Defects” or “Defect-Driven Testing” [Duvall 2007]
- version control on code, test data and build/deployment scripts with frequent commits; therefore, you need to make small changes and commit after each task [Duvall 2007]
- automated build with a comprehensive automated test suite and alert mechanisms [Humble 2011]
- rollback procedures integrated into the pipeline [Edelman 2018]
- agreement of the team to support the generation, improvement and maintenance of the pipeline [Humble 2011]
This enables [Duvall 2007]
- labeling code repository assets,
- producing a clean environment,
- running reproducible tests against a well-defined version and rollbacks to aim at releasing working software at any time.
To make this possible, the pipeline usually relies on tools with Command Line Interface (CLI) or RESTful API which handle mainly XML/HTML/JSON data.
Finally, even if CI runs tests for you, experienced Team run locally the tests, then integrate changes from other Team Members [Humble 2011]. In terms of TDD, the CI should stop on RED tests (unit and other). If RED code is committed, the CI may be run and fail. Other Team Members may also pull the failing code and slow them down.
To avoid that, the pipeline may be run from a temporary branch but it would lead to integration issues if branch merging would occur late.
A more mature approach would be to turn the code to GREEN before committing. Unfortunately, in most cases it’s not enough. The use of pipeline tools with “pretested commit”, “personal build”, or “preflight build” features then is necessary [Humble 2011].
As a start, to make a pipeline always available for delivery, the mindset should be “never go home on a broken build”, even if it means doing your last commit an hour before you end your day [Humble 2011].
To enable high availability, it is necessary to watch at pipeline status to enable an Andon reaction when everyone is responsible for the pipeline [Humble 2011] and introduce Jidoka from defects met on the production code [Duvall 2007] and false positives as well to make the pipeline more robust [Moustier 2022]. To improve the pipeline into an “always GREEN” pipeline, Teams may be led to revert the pipeline if a fix is not provided within a given timebox [Humble 2011].
Fixing broken builds immediately should be a top project priority [Duvall 2007]. This approach is actually a Kaizen approach which aims at the so-called “zero defect” [Lindström 2020].
Impact on the testing maturity
CI is one of the 13 practices claimed by XP [Beck 2001. Nowadays, most Teams try to embed the whole pipeline phases. The reason is that without CI, software changes are often made in large batches which may take months to have some feedback on features.
This lack of feedback is also caused by the lack of people who are not interested in running the whole product until it is finished [Humble 2011]. It's a human tendency to be so focused on implementation that they no longer see the big picture, simply because it takes extra effort to get one’s nose off the handlebars. The drawback of this kind of situation is that it generates incredibly long feedback loops, and it also takes a very long time for issues to be addressed. As a result, features take much longer to develop, and the quality of service is reduced. [Edelman 2018] [Humble 2011].
Actually, the presence of a pipeline enables Developers to simply make changes and push them directly into production thanks to a fast pipeline. This will enable Team Members to have fast feedback on the whole solution [Duvall 2007]. To generate a good delivery flow required in agile, a 10’ pipeline on Dev cycle level is also an objective [Humble 2011]. This timebox is a kind of SMED for Customers which leverages their own business agility [SAFe 2021-40]; therefore, CI is a Centerpiece for Quality and thus provides the technical foundations for a Continuous Testing approach [Duvall 2007].
The 10’ timebox seen above is actually a hard target. The difficulties comes from the obvious large amount of tests candidate for being run by the CI/CD along with the many tasks performed at CI, notably
- building of binaries from production code
- continuous inspections [Duvall 2007] (Code Quality, code coverage, code duplication),
- on-demand environment generation [Edelman 2018]
Therefore, you should
- keep the Build and Test Process short [Humble 2011] - notably by running only Sanity checks in CI that should cover most features
- mock components that would introduce delays and hard to repeat tests due to network or database access [Duvall 2007]
As a consequence, all permutations and edge cases out of the sanity check should be run separately [Axelrod 2018] with secondary builds or on periodic intervals [Duvall 2007] with extra pipelines. Those pipelines should match your delivery flow and the feedback loops expectation levels.
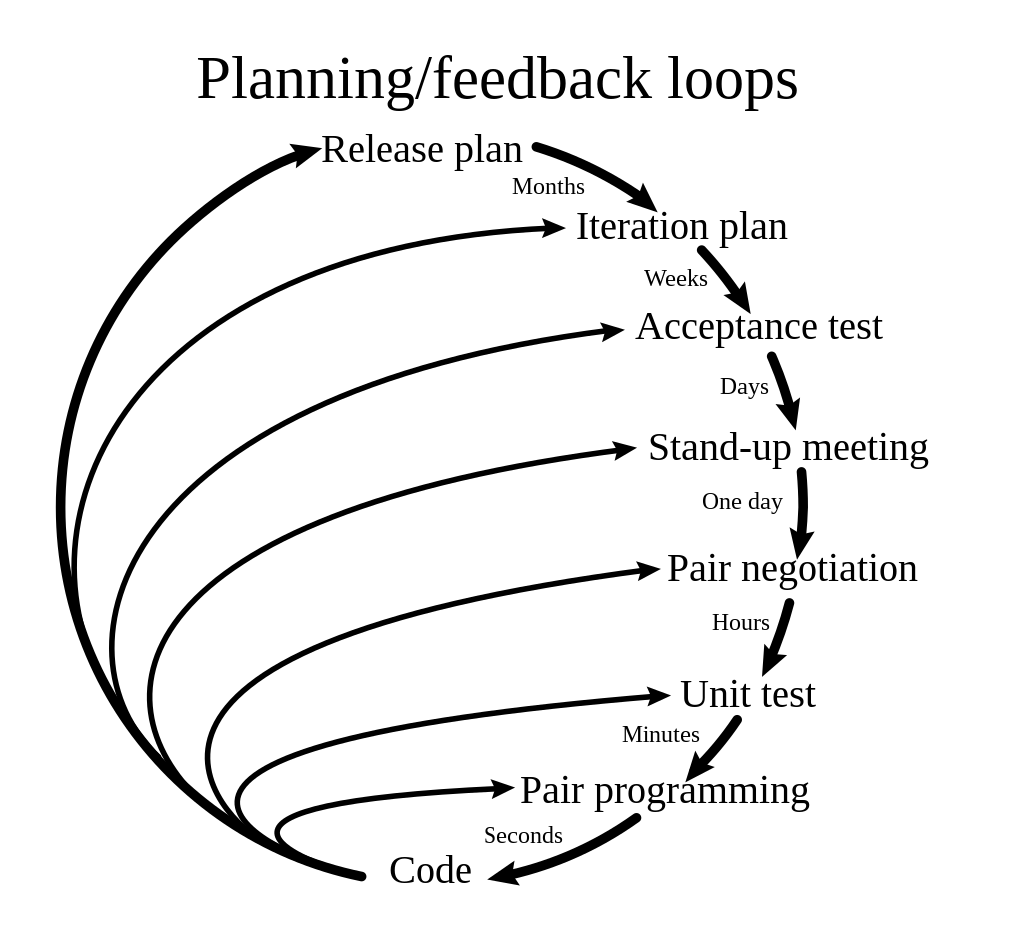
These feedback loops should adapt the pipeline contents with a compromise between
- feedback loops expectations
- timebox related to the loop duration
- scripts durations to match the timebox
- Shift Left Testing which requires feedbacks as soon as possible
This highlights the need to provide multiple pipelines to address the timebox matter, for example:
- a synchronous 10’ CI/CD pipeline triggered right after committing some code changes
- an asynchronous CI/CD pipeline launched for instance during the night with a few hours timebox
- a sprint-long timeboxed CI/CD to run very slow scripts such as SAST analysis [Hsu 2018], load testing or data migrations [Nygard 2018] which may last several days
When it comes to large companies, multiple pipelines running in parallel becomes even more obvious since it would take days to build several millions of lines of code at once. Architecture and organization should then ease pipeline design, notably through
- microservices [Nygard 2018]
- Value Stream-based pipelines [SAFe 2021-18]
- or inspired by the “Team Topology” approach [Skelton 2019].
In this context, working in a cadenced and synchronized manner becomes as difficult as it is challenging; fortunately, this can be facilitated by Dark Launch / Canary Releasing strategies to make the delivery process resilient to timing issues.
If the automation strategy of the organization makes end-to-end testing scripts possible with multiple parts delivered by several departments, the need of a pipeline to gather them all emerges, the use of a decentralized CMDB along [Humble 2011] and so is the use of toggle flags to control the configuration of those environments.
Agilitest’s standpoint on this practice
Agilitest is extremely concerned with the DevOps matter, this is why the tool can be plugged to Jenkins, the most used orchestrator in software companies.
Since Agilitest scripts are saved under a text format, they can easily take part of the CMDB with Git. The text format enables scripts merging with a simple text editor.
The tool can be involved in all pipelines levels, from Development Team level to product management thanks to its #nocode approach since it does not require any development skills.
The spreading of Agilitest scripts across the organization is also facilitated by an open source script running engine [Pierrehub2b 2021]. It thus enables the scaling of test scripts automation for free.
To discover the whole set of practices, click here.
Related cards
To go further
- [Beck 2001] : Kent Beck & Cynthia Andres - 2001 - “Extreme Programming Explained: Embrace Change” - isbn:9780321278654
- [Booch 1994] : Grady Booch - 1994 (1st ed. 1991) - ”Object-Oriented Analysis and Design with Applications” - isbn:9780805353402
- [Cosgrove 2021]: Kat Cosgrove - OCT 2021 - “A History of CI/CD” - https://www.youtube.com/watch?v=aRlgmbSEhbQ
- [Deloitte 2020] : Deloitte - APR 2020 - “DevOps Point of View An Enterprise Architecture perspective” - https://www2.deloitte.com/content/dam/Deloitte/nl/Documents/technology/deloitte-nl-etp-devops-point-of-view.pdf
- [DonWells 2013] : DonWells - JUL 2013 - “Planning and feedback loops in extreme programming” - https://en.wikipedia.org/wiki/Extreme_programming#/media/File:Extreme_Programming.svg
- [Duvall 2007] : Paul M. Duvall & Steve Matyas & Andrew Glover - 2007 - “Continuous Integration: Improving Software Quality and Reducing Risk” - isbn:9780321336385
- [Edelman 2018] : Jason Edelman & Scott S. Lowe & Matt Oswalt - 2018 - “Network Programmability and Automation” - isbn:9781491931257
- [Fowler 2006] : Martin Fowler - MAY 2006 - “Continuous Integration” - https://martinfowler.com/articles/continuousIntegration.html
- [Gothelf 2013] : Jeff Gothelf & Josh Seiden - « Lean UX - Applying Lean Principles to Improve User Experience » - O’Reilly - ISBN: 978-1-449-31165-0
- [Gray 2009] : Dave Gray - « Empathy Map » - 12/NOV/2009 - https://gamestorming.com/empathy-map/
- [Hsu 2018] : Tony Hsu - 2018 - “Hands-On Security in DevOps: Ensure Continuous Security, Deployment, and Delivery With DevSecOps” - isbn:9781788995504
- [Humble 2011] : Jez Humble - 2011 - “Continuous Delivery : Reliable Software Releases Through Build, Test, and Deployment Automation” - isbn:9788131757369
- [Lewrick 2018] : Michael Lewrick, Patrick Link & Larry Leifer - « The Design Thinking Playbook Mindful digital transformation of teams, products, services, businesses and ecosystems » - Wiley - 2018 - ISBN 978-1-119-46747-2
- [Lindström 2020] : John Lindström, Petter Kyösti, Wolfgang Birk & Erik Lejon - JUL 2020 - “An Initial Model for Zero Defect Manufacturing” - https://mdpi-res.com/d_attachment/applsci/applsci-10-04570/article_deploy/applsci-10-04570.pdf
- [Moustier 2022] : Christophe Moustier - AVR 2022 - “My Flaky Test is agile!” - https://www.youtube.com/watch?v=Ptg5NICosNY&t=2708s
- [Nygard 2018] : Michael T. Nygard - 2018 - “Release It!: Design and Deploy Production-Ready Software” - isbn:9781680502398
- [Pierrehub2b 2021] : Pierrehub2b - MAI 2021 - “Projet actiontestscript” - https://github.com/pierrehub2b/actiontestscript
- [Ratcliffe 2012]: Lindsay Ratcliffe & Marc McNeill - AUG 2012 - “Agile Experience Design: A Digital Designer's Guide to Agile, Lean, and Continuous” - isbn:9780321804815
- [Ries 2012] : Eric Ries - « Lean start-up » - Pearson - 2012 - ISBN 978-2744065088
- [SAFe 2021-18] : SAFe - FEV 2021 - “Value Stream” - https://www.scaledagileframework.com/value-streams/
- [SAFe 2021-40] : SAFe - JUL 2021 - “Business Agility” - https://www.scaledagileframework.com/business-agility/
- [SAFe 2021-46]: SAFe - FEV 2021 - “Continuous Delivery Pipeline” - https://www.scaledagileframework.com/continuous-delivery-pipeline/
- [Skelton 2019] : Matthew Skelton & Manuel Pais - 2019 - “Team Topologies: Organizing Business and Technology Teams for Fast Flow” - isbn:9781942788829


{kind=link}